WARNING!
This blog post contains answers to the questions I’ve asked in my “PMTUD or not? Troubleshooting case” article. If you want to work through them yourself, do not read the following.
Ok, let’s start. First I want to say that these answers are just my thoughts, and if you don’t agree – welcome to have a discussion. Maybe I’ll learn a lot of new things, and this is always great.
So,
Standalone question 1. Why the first thing I did was the server side capture?
My answer consists of two parts.
The first part: as Jasper has commented, I wanted to check whether my (client) packets have got to NAS unchanged. A lot of middleboxes can alter different fields, particularly MSS value:
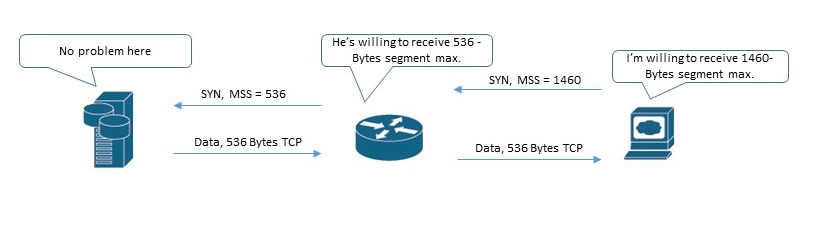
Not all parts of conversation are shown here, of course. Just the main point.
The second part: I wanted to be sure whether PMTUD process is actually happening or not. If we capture on receiving side, we don’t see PMTUD process, because it’s happening on the “server <–> some router on the path” part of the network! In case we are sending quite large requests, we would see PMTUD on our side, but this would be totally another independent process.
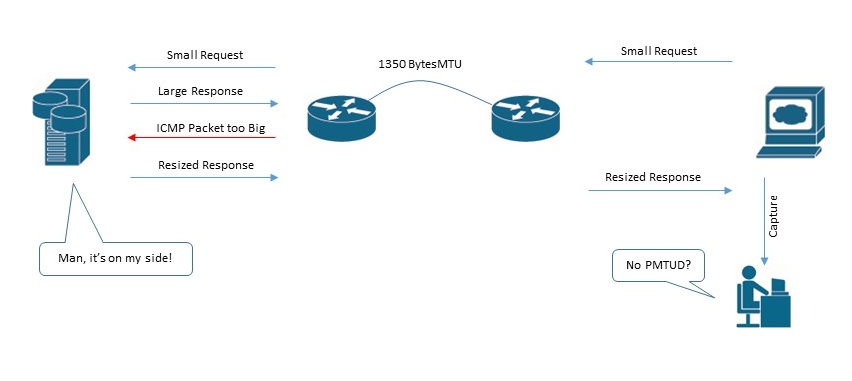
In our case there actually was no PMTUD process happening on the server side (conversation between 192.168.112.77 and 192.168.1.115 hosts)
Questions based on PCAP.
Question 1. Look at packets 120-124. Why are they considered “out-of-order” (not “retransmissions”, not “spurious retransmissions”, not “fast retransmissions”)?
Here we gonna use Wireshark TCP dissector source code (Wireshark.org – Develop – Browse the Code – Epan – Dissectors – packet-tcp.c) and RFC’s.
Let’s start “from the opposite”.
“Spurious retransmission”. From dissector source code: “If the current seq + segment length is less than or equal to the receiver’s lastack, the packet contains duplicate data and may be considered spurious.”
So, spurious retransmission is the retransmission of the data already ACK’ed by the receiver. In our case we didn’t see any ACKs for large segments, because these large segments have been successfully dropped by the router. I want to say also that our perspective (the placement of capturing device) is very important in that case and we have much more chances to see “spurious retransmissions” if we capture on client-side rather than on server-side. Why? Let’s draw a diagram (I’m speaking about one-way data transfer now).
If we are capturing on client side:
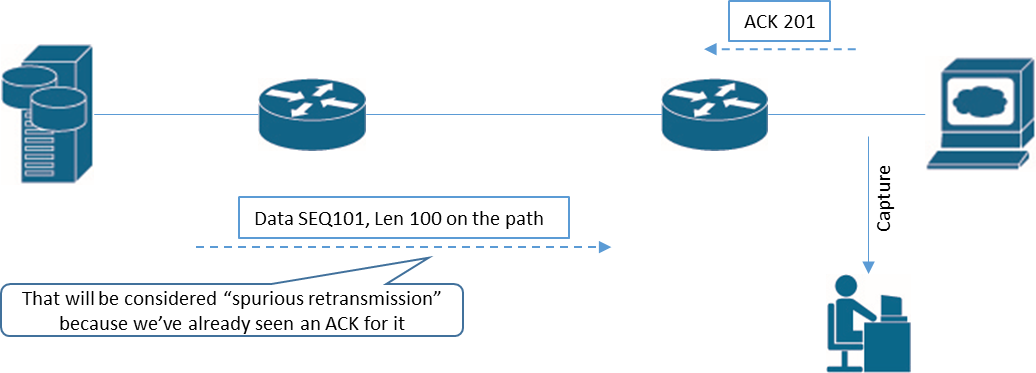
Compare it with the next situation (the SAME situation but with another capture point actually):
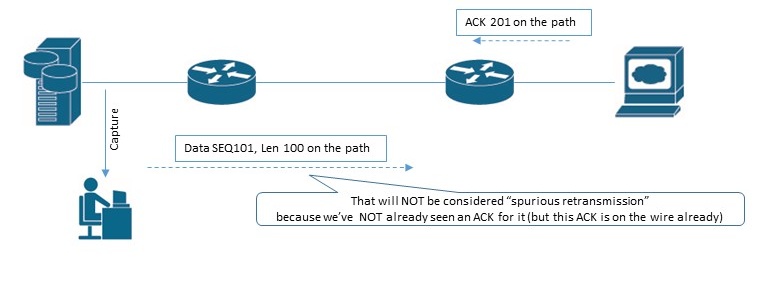
Try to rearrange ACK and DATA packets on the second diagram for you to see DATA packet as “spurious retransmission” 😉 Not so easy, right? If the server has already seen ACK 201, it will not send DATA SEQ 101 packet anymore. Unless it’s completely crazy, or ACK packet has wrong IP (or any other) checksum and therefore are going to be discarded by server’s IP stack, or ACK packet is already received by the server, but is not processed yet (this is very tiny moment in term of time).
“Fast retransmission”. This is easy one. Fast retransmission needs to be caused by duplicate ACK’s. From RFC 2581: “The fast retransmit algorithm uses the arrival of 3 duplicate ACKs (4 identical ACKs without the arrival of any other intervening packets) as an indication that a segment has been lost. After receiving 3 duplicate ACKs, TCP performs a retransmission of what appears to be the missing segment, without waiting for the retransmission timer to expire.”
From dissector source code: “If there were >=2 duplicate ACKs in the reverse direction (there might be duplicate acks missing from the trace) and if this sequence number matches those ACKs and if the packet occurs within 20ms of the last duplicate ack then this is a fast retransmission”
In other words, no dup ACKs –> no “Fast retransmission”!
“Retransmission” vs “Out-of order”. This is tough one. Dissector source code says: “If the segment came relatively close since the segment with the highest seen sequence number and it doesn’t look like a retransmission then it is an OUT-OF-ORDER segment”.
A little bit general description, isn’t it? I think it all comes to timings and sequence numbers here. Packet 120 came with delay of just 1,3 milliseconds from packet 118, and it had different (lower) sequence number than packet 118. Perhaps that’s the all logic.
Question 2. Why ICMP Type 3 / Code 4 packets from 192.168.1.1 (router IP) have 590-Bytes size?
Let’s split this question in two parts.
a) What is the lower limit for ICMP Type 3 / Code 4 packets? According to RFC 792 ICMP Type 3 packets must have the next structure:

So, the minimum size is: 20 (IP header of ICMP packet) + 8 (ICMP header) + 20 (IP header of original datagram) + 8 (64bits/8 of original data datagram) = 56 Bytes on L3.
b) What determines the upper limit for the same packet? It is router’s unwillingness to turn into ICMP black hole. Router doesn’t know, maybe there are another devices between it and the server (in our case) with the same low-PMTU problems. Yes, we know that big DATA packet has come to us successfully, but how can we be sure that our ICMP packet will go back the same way? We can’t know that.
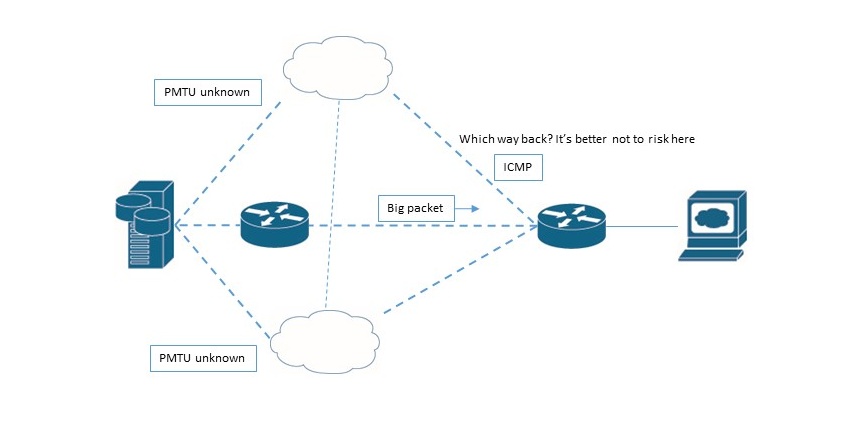
And it’s absolutely not good, if our ICMP packet suddenly will be dropped by someone on the path. If ICMP packet is dropped, it will not be retransmitted. So, our router sets the ICMP packet size to the size that will be definitely forwarded.
But why exactly 576-Bytes L3 size (590-Bytes frame)? Why not 125 Bytes or not the minimum? Hmm… honestly, I’ve not found any explanation for that but I suspect this depends on OS that sends such ICMPs. “Just because we can! Why not? Take as much as possible as far as there is no risk for ICMP packet to be dropped because of its large size” 🙂 Correct me if I’m wrong here. I don’t know the exact answer.
Both my traces have been captured on Mikrotik routers. If you have a possibility, you can check how it happens on your hardware and share this information.
UPD. Christian has added a great comment regarding this question:
“RFC 792 defines the “original datagram” field for ICMPv4
messages. In RFC 792, the “original datagram” field includes the IP
header plus the next eight octets of the original datagram.
[RFC1812] extends the “original datagram” field to contain as many
octets as possible without causing the ICMP message to exceed the
minimum IPv4 reassembly buffer size (i.e., 576 octets).
RFC 4884 defines a length for the ICMPv4 type=3 message.
In RFC1812 Section 4.3.2.3 you got an answer why the
ICMP Frame is 590 Bytes long.
RFC1812 Section 4.3.2.3 Original Message Header
Historically, every ICMP error message has included the Internet
header and at least the first 8 data bytes of the datagram that
triggered the error. This is no longer adequate, due to the use of
IP-in-IP tunneling and other technologies. Therefore, the ICMP
datagram SHOULD contain as much of the original datagram as possible
without the length of the ICMP datagram exceeding 576 bytes. The
returned IP header (and user data) MUST be identical to that which
was received, except that the router is not required to undo any
modifications to the IP header that are normally performed in
forwarding that were performed before the error was detected (e.g.,
decrementing the TTL, or updating options). Note that the
requirements of Section [4.3.3.5] supersede this requirement in some
cases (i.e., for a Parameter Problem message, if the problem is in a
modified field, the router must undo the modification). See Section
[4.3.3.5]).”
Thanks for that information!
Question 3. Why is packet no. 130 NOT considered “Dup ACK” despite it has ACK number 6469 (relative), the same ACK number as packet no.128 already had? And after that packet no. 132 with the same ACK number of 6469 IS again considered Dup ACK.
From RFC 5681: “An acknowledgement is considered a “duplicate” in the following algorithms when (a) the receiver of the ACK has outstanding data, (b) the incoming acknowledgement carries no data, (c) the SYN and FIN bits are both off, (d) the acknowledgement number is equal to the greatest acknowledgement received on the given connection (TCP.UNA from [RFC793]) and (e) the advertised window in the incoming acknowledgement equals the advertised window in the last incoming acknowledgement.”
Our packet carries data (130-Bytes TCP segment), condition (b) is not met, so it can’t be considered “dup ack”. That’s it. There is actually some ground behind such behavior, could you guess what exactly?
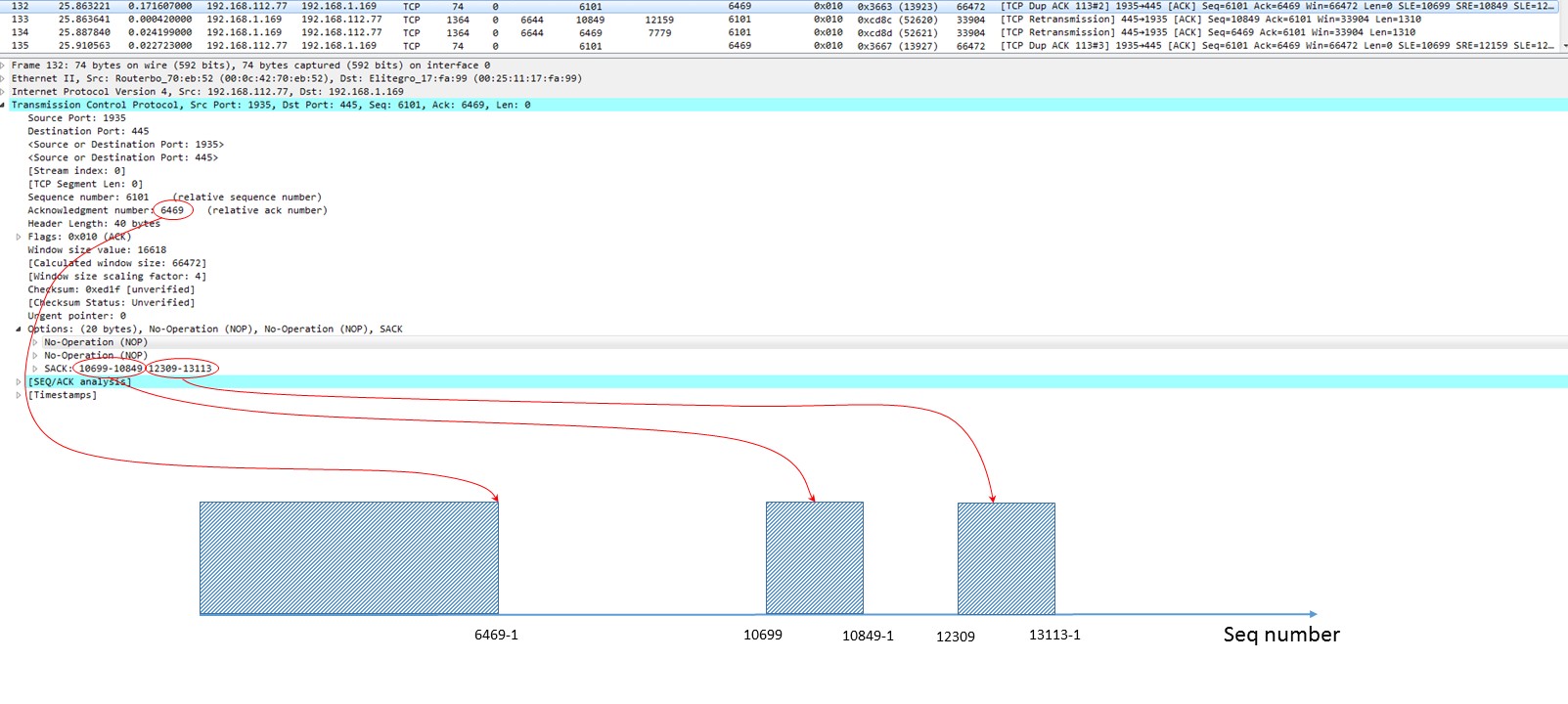
Question 4. What do you think, did the packet no. 133 get to the receiver successfully or got lost on the path?
Yes, it did. It got there. It was never retransmitted; packet 147 acknowledged it. The cool thing here is that we can prove it even earlier prior to packet 147. Compare two ACKs from the client: no. 132 and no. 135. They both are SACK’s. They both seem to be identical, BUT! Look at the SRE (Right edge) field. It has been changed! Packet no. 132 had SRE of 10849, while packet no.135 has SRE of 12159. The range of successfully received chunk has been changed from “10699…10849-1” to “10699…12159-1”.
Situation at the receiver after it had emitted packet 132:
And after it had emitted packet 135:
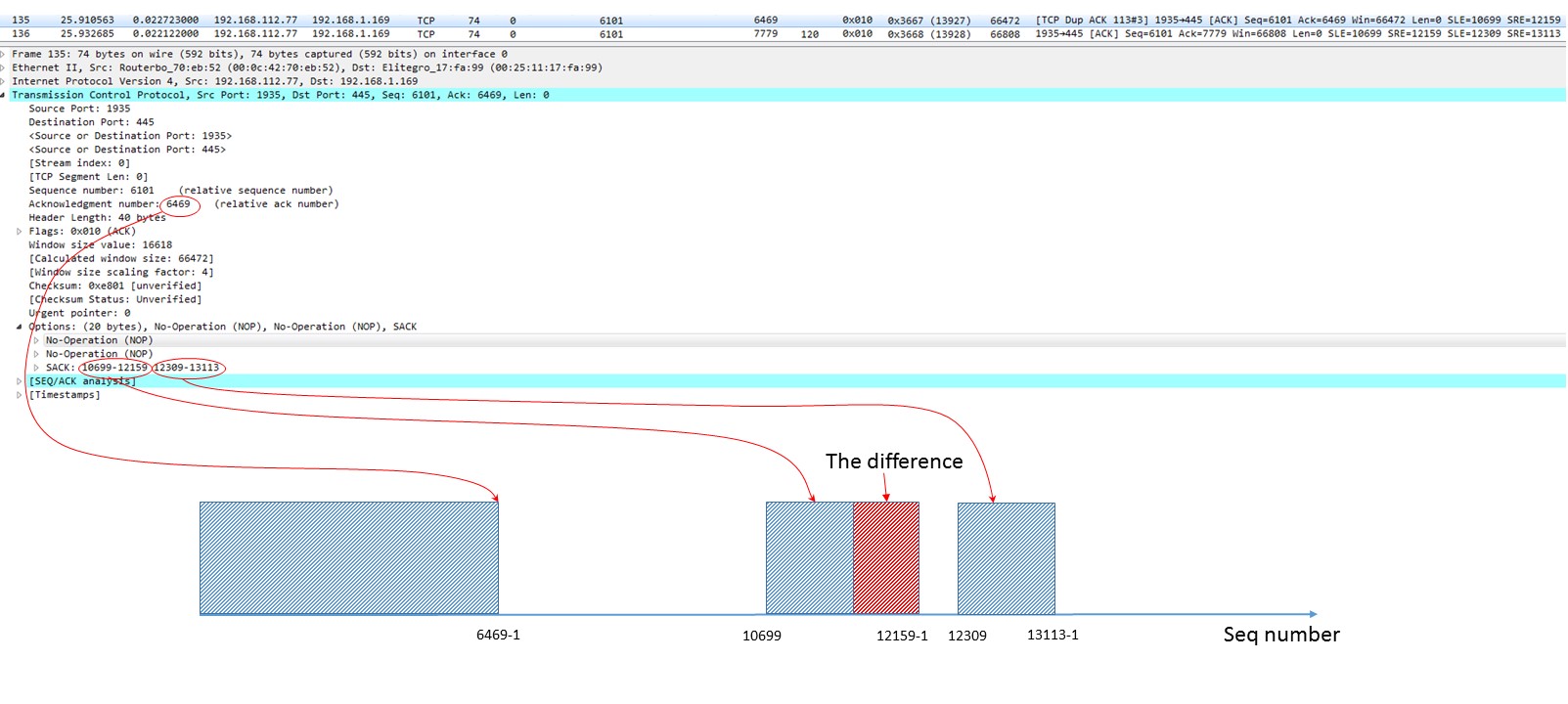
Why have I written those “-1” on the graph? Because Left and Right edges mean different things:
- Left Edge of Block:
This is the first sequence number of this block.
- Right Edge of Block:
This is the sequence number immediately following the last sequence number of this block (RFC 2018).
So, Left edge means the first Byte we already have, Right edge means the first Byte of some block we’ve yet to receive.
The bottom line is: data packet 133 with SEQ number 10849 arrived to client and filled some gap in the received stream. But this gap was not the only one in receiver’s buffer, so ACK number in the second Dup ACK (packet no. 135) has not been changed.
Question 5. Assume you are capturing on a server side. The server has just started to upload quite large file. PMTUD has been already completed, PMTU size has been successfully discovered. What do you think, do you have a chance to see it happening again in the same TCP stream (or caused by the same TCP stream)?
Once the sender has figured out PMTU size of 1350 Bytes it will use this size in the current TCP stream, and therefore we will not see PMTUD anymore. Right? Wrong! 🙂 The correct answer is… It depends! On what?
- On the permanence of our data path.
- On TCP stack of our server (sender).
Case (a). We cannot guarantee that our path will be the same all the time. At some point of time just in the middle of the transfer process some router on our path could become unreachable, so dynamic routing protocol will choose another path with PMTU of, say, 1300 Bytes (or whatever other less than 1350 Bytes). Here you go! Catch ICMP Type 3 / Code 4 packet!
Case (b). Look at the next part of RFC 1191:
“Hosts using PMTU Discovery MUST detect decreases in Path MTU as fast as possible. Hosts MAY detect increases in Path MTU, but because doing so requires sending datagrams larger than the current estimated PMTU, and because the likelihood is that the PMTU will not have increased, this MUST be done at infrequent intervals. An attempt to detect an increase (by sending a datagram larger than the current estimate) MUST NOT be done less than 5 minutes after a Datagram Too Big message has been received for the given destination, or less than 1 minute after a previous, successful attempted increase. We recommend setting these timers at twice their minimum values (10 minutes and 2 minutes, respectively)”.
So yes again, according to RFC 1191 host can increase its MTU size to probe the path. If it wants to do so. It means that we indeed have a chance to see PMTUD happening again.
Your comments to my previous blog post inspired me to laern different OS behavior regarding PMTUD. So, I performed a little test. Here you can see some results I’ve got:
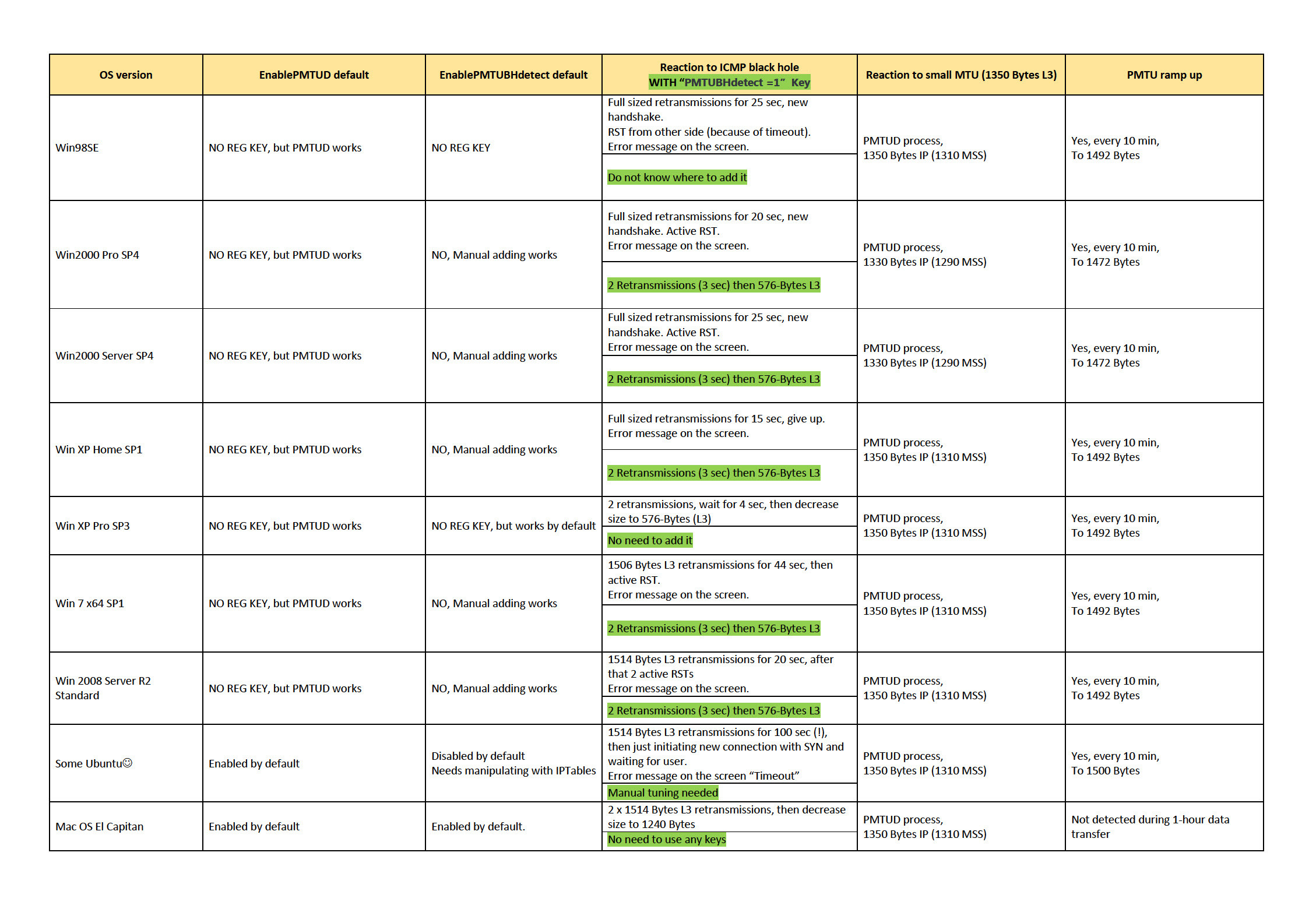
All OS versions I’ve tested actually ramped PMTU size up once every 10 minutes. Mac OS.v.10.something “El Capitan” didn’t do that at all. Also I’ve recorded the behavior when facing with ICMP Black Hole. I hope you’ll find that information useful. Leave request if you want me to test some other OS.
Some interesting observations in there:
- Windows 2000 decreases L3 PMTU to 1330 Bytes, not to 1350 Bytes stated in ICMP Packet too Big.
- Only Windows XP Pro SP3 (out of all tested Windows versions) has PMTU Black Hole Detection turned on by default.
- Most of OS versions ramped PMTU up to the size of 1492 Bytes, NOT to initial 1500 Bytes (L3). Why is that? Besause there’s such recommendation in RFC1191: “ A better approach is to periodically increase the PMTU estimate to the next-highest value in the plateau table (or the first-hop MTU, if that is smaller)” (Section 7.1). The next value for us in “plateau table” is exactly 1492 Bytes.
So, that was good excersice! As always, you’re welcome to leave any comment!
Hi Vladimir,
great article again!
But I got a little different answer of Question 2
My answer is the following:
RFC 792 defines the “original datagram” field for ICMPv4
messages. In RFC 792, the “original datagram” field includes the IP
header plus the next eight octets of the original datagram.
[RFC1812] extends the “original datagram” field to contain as many
octets as possible without causing the ICMP message to exceed the
minimum IPv4 reassembly buffer size (i.e., 576 octets).
RFC 4884 defines a length for the ICMPv4 type=3 message.
In RFC1812 Section 4.3.2.3 you got an answer why the
ICMP Frame is 590 Bytes long.
RFC1812 Section 4.3.2.3 Original Message Header
Historically, every ICMP error message has included the Internet
header and at least the first 8 data bytes of the datagram that
triggered the error. This is no longer adequate, due to the use of
IP-in-IP tunneling and other technologies. Therefore, the ICMP
datagram SHOULD contain as much of the original datagram as possible
without the length of the ICMP datagram exceeding 576 bytes. The
returned IP header (and user data) MUST be identical to that which
was received, except that the router is not required to undo any
modifications to the IP header that are normally performed in
forwarding that were performed before the error was detected (e.g.,
decrementing the TTL, or updating options). Note that the
requirements of Section [4.3.3.5] supersede this requirement in some
cases (i.e., for a Parameter Problem message, if the problem is in a
modified field, the router must undo the modification). See Section
[4.3.3.5]).
Hi Christian,
This is a great comment, thanks!
I’ve added information you provided into post.
Regards,
Vladimir
Well done on that very detailed and interesting post Vladimir.. Kudos for taking the time and effort to really dig down into the details. It is great to be able learn by making oneself think of various things. Your questions really forced some quality thinking. I especially like your table of different operating system versions listing their differing MTU behaviours.
In your capture files, I notice that the SYN/SYN-ACK were not tampered with by any middlebox (as you describe in your first diagram). The 3-way handshake for your connection shows an MSS of 1460 for both. My opinion is that it would be better if your VPN endpoints did do such tampering to reduce the MSS value to 1310 – meaning that there would then be no need for the large packet drops and associated ICMP responses.
Cisco has a command “ip tcp adjust-mss” and a bit of Googling tells me that Mikrotik might use “clamp-mss” instead.
I’d be interested to hear other opinions on this.
HI Philip,
But back to your question
the “ip tcp adjust-mss” command is of course very interesting.
But there are at least two more parameters on a cisco system which comes into play:
1. ip mtu
2. tunnel path-mtu-discovery
So normally we should manage PMTUD is working, maybe due to the use of “tunnel path-mtu-discovery”.
And some FW rules.
But to prevent the PMTUD process for the most connections the adjusting of the MSS is an option I think.
Especially for a tunnel to a Branchoffice. I wish my DSL router at home could do this, too. Because I don´t want to downsize my MTU on all my home devices.
That is an example where it would be very usefull. for me.
Furthermore I think a lot of tunnel concepts (for example a GRE-IPsec) have problems with the right MTU. Where the 3 options could be needed.
I found an interesting description with a lot of tunneling use cases here:
http://www.cisco.com/c/en/us/support/docs/ip/generic-routing-encapsulation-gre/25885-pmtud-ipfrag.html
So everybody should find the right use case for him. and can decde if he wants to tune this behaviour.
Philip, Christian,
Thanks for the feedback!
Mikrotik can do this using command like the next:
add out-interface=pppoe-out protocol=tcp tcp-flags=syn action=change-mss new-mss=1300 chain=forward
(This is just a sample, I used slightly different command).
I tried to do that today and it actually works. You can look at the traces from both capture points here:
http://www.packettrain.net/wp-content/uploads/2016/10/mikrotik_traces.zip
You can track changes in SYN packets and also data transfer starts with 1350- Byte packets without any PMTUD process.
Of course, it will work only with TCP – no SYN packets are in UDP 🙂
Christian,
If Mikrotik acts as PPPoE-client through DSL-modem in bridge mode (one of ours has such config), it even adds MSS reducing option automatically (to 1440 Bytes L3) .
It’s a cool point regarding manual MTU changing on your devices. We must consider that such a task can be very time-consuming depending on how many devices you have. And sometimes it’s just impossible (for instance, there is not so much probability for your printer or “smart fridge” to allow you changing their MTU).
Ah yes Vladimir, I see in the captures that you modified the MSS to 1310.
We now get the client and server each specifying MSS=1460 in their SYNs and SYN-ACKs, but both being told that the other end can only support 1310 (because your Mikrotiks adjusted the SYNs and SYN-ACKs as they passed through.
I note that this now saves you the 650ms+ of time wasted to handle the ICMP packets, the retransmission of the original 1460’s into 1310+150 as well as the associated packet losses, SACKs and extra retransmission timeout.