One day when I had a couple of free minutes I decided to perform some baselining in our office network.
The Problem
This time my eye caught an interesting pattern in our NAS device traffic. Look at the screenshot below:
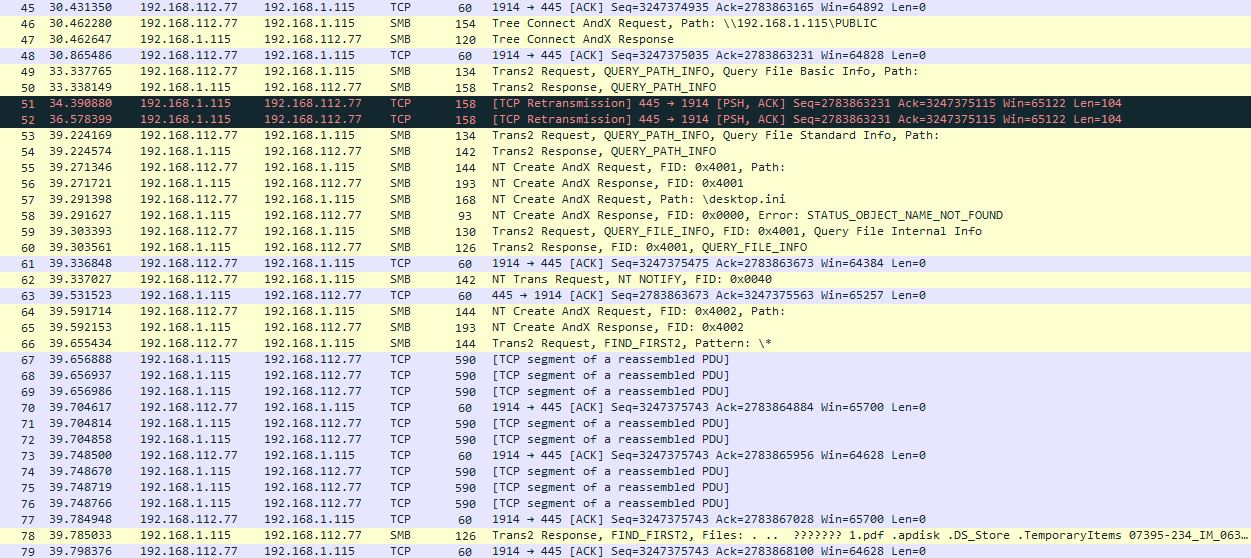
You see it? Maybe a couple of retransmissions? They may seem interesting. Delay of 6 seconds – it’s quite large to pay attention to it. But honestly there was some NFS-related stuff happening on the background that I’ve filtered out from the trace. So that’s not what I want to show you.
Now I’m talking about all those packets starting from number 67. All of them are 590 bytes in size. Of course, there are many packets, that are even less in size we can see before packet 67, BUT “TCP segment of a reassembled PDU” sign and the same size of 590 bytes tell us clearly that after packet 67 there must be fully-loaded packets. Fully-loaded packets of only 590 bytes size? Why is that?
I suspect the most experienced readers has already guessed the cause, but we’ll move on step-by step with some methodology and fun conversation with tech support. Let’s check 3-way handshake, maybe we’ll find some clue in it:
![]()
So far so good, both endpoints declare 1460-Bytes MSS, SACK is enabled, window scaling is enabled. The NAS declares WS of only 1, but.. Is it a problem? Potentially maybe, but for now it’s not. Let’s check timings. We’re capturing on server-side. Strictly saying, the very first trace I captured was client-side one, but then server-side capture was taken additionally (guess why I did so and leave a comment below).
Here I have to mention (and you can see it also in IP address columns) that my client machine is in 192.168.112.0/24 subnet whereas NAS box is in another 192.168.1.0/24 subnet. Even more, NAS box is in another location, and we have site-to-site IPSec VPN between these two locations.
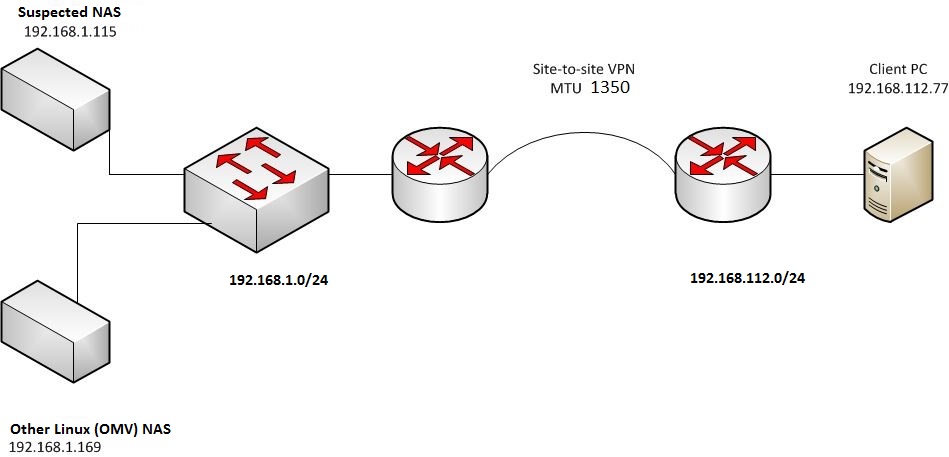
I captured another trace within the 192.168.1.0/24 subnet and figured out, that there was no problem in this case – NAS box used 1514-bytes Ethernet frames within the same subnet like it should do normally.
So, suspecting a NAS OS problem or misconfiguration I sent an e-mail to manufacturer’s tech support with the description of that situation and also with attached PCAP.
They replied to me:
“…In regards to your issue, I understand when you’re using a NAS device and on the local subnet the packet size is 1500 bytes. When you are trying to access the NAS from another subnet, the packet size decreased to 576 bytes.
Researching this information online, I suspect the issue is somewhere within the network setup that is limiting the packet size when accessing the data from another subnet…”
..And they gave me a link with PMTUD description.
OK, I’ve got it. Typical answer of “this is your network” type. But I know for sure that VPN channel has 1350-bytes MTU, not the minimal 576-bytes. So let’s have a little IT-combat then 🙂
I captured a trace in the same environment, but from another NAS that has Debian-based OpenMediaVault OS onboard (IP of 192.168.1.169):
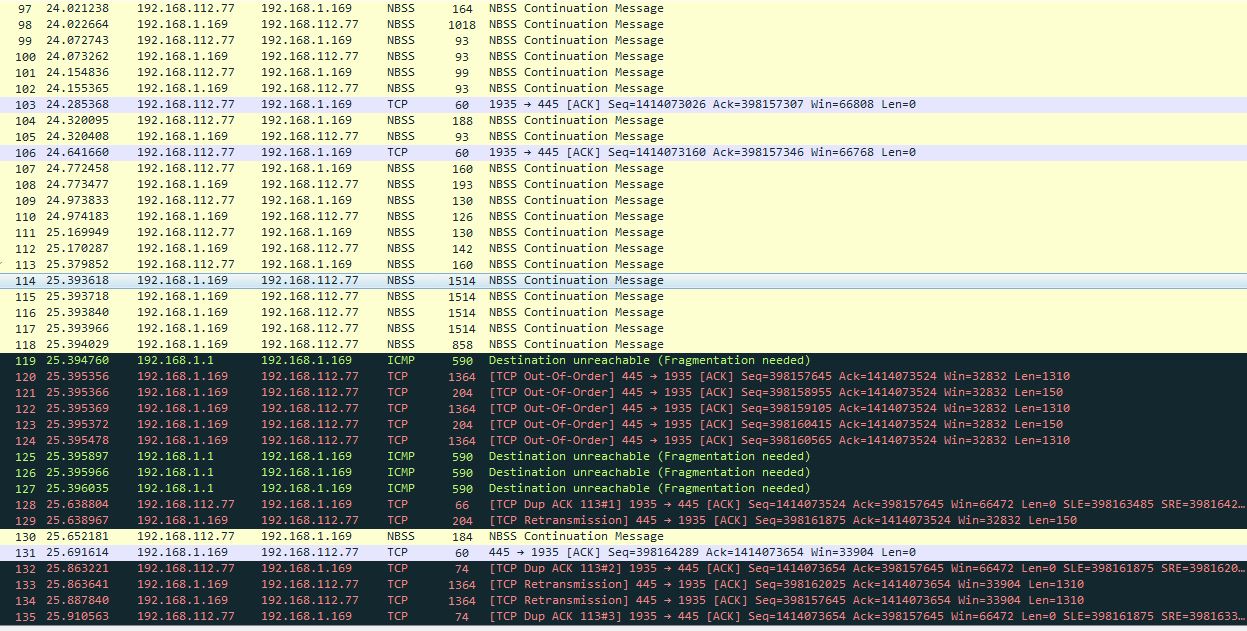
This is how real PMTUD must look like. At first consider the packet no.98. It has 1018 – 14 = 1004 Bytes in size (on L3) and it passed through VPN without errors! (Actually, I suspected it but anyway it’s cool to confirm that I was right).
Later four full 1514-Bytes frames 114-117 were sent by server, and… yup, they were dropped by the router with the returning of ICMP Type 3 / Code 4 / Destination unreachable (Fragmentation needed).
Check out “MTU of next hop” field in those ICMP’s:

After OMV-NAS had received that ICMP, it divided outgoing packet into two parts of 1350 Bytes and the rest (1364 and 204-Byte Ethernet-frames respectively) and sent them sequentially. Let’s do some math here: 1364 – 14 (L2 header) = 1350Bytes – 40 (L3 header + L4 header, thanks for the comment, Jasper) = 1310 Bytes is the first TCP segment. 204 – 14 (L2 header) = 190 Bytes – 40 (L3 header + L4 header) = 150 Bytes is the second TCP segment. Total: 1310 Bytes + 150 Bytes = 1460 Bytes of initial MSS. This is perfect match!
Analysing a behavior of the second NAS, we can eliminate the network – it works normally with this device.
Knowing that, I sent another e-mail to tech support with the message:
“Thank you for the link, but where do you actually see PMTUD operation in my trace? It must be looking like the next… (and I attached trace #2 with Linux-OMV-NAS conversation)”
While waiting for the reply (it took much longer this time) I opened RFC1191. Well, maybe something is there that could give me an answer.
“Actually, many TCP implementations always send an MSS option, but set the value to 536 if the destination is non-local. This behavior was correct when the Internet was full of hosts that did not follow the rule that datagrams larger than 576 octets should not be sent to non-local destinations. Now that most hosts do follow this rule, it is unnecessary to limit the value in the TCP MSS option to 536 for non-local peers.”
That is close, our NAS set 1460 as TCP MSS (consider 3-way handshake above). And it follows the rule to send 576-octets packets to non-local destinations…
In the meantime the next reply arrived to me:
“Something to try is to manually set the parameters for the MTU on the NAS device. Try the next solution:
netsh interface ipv4 set subinterface “Local Area Connection” mtu=1300 store=persistent
in the command line of the device.”
Arguable solution considering the fact that in the same subnet all worked perfectly. But anyway I couldn’t do that because the NAS has Windows XP Embedded onboard, and it doesn’t allow me to get to the CLI. That is very limited OS edition with custom simplistic shell instead of explorer.
So after a small conversation tech support guy admitted, that he can’t help me because this device is obsolete and they won’t make any firmware update for it anymore.
The solution
There was a good time to give up – we’ve already proven that the NAS itself is responsible for an issue; tech support refused to help me, but… I was lucky to realize that I can enter BIOS of the NAS and also can change boot order to “USB first”! Cool news.
So, it’s time to make a bootable USB flash drive with Live Windows (ERD Commander) on it. This piece of software has built-in registry editor, it can discover installed OS and edit its registry.
I booted from that USB…
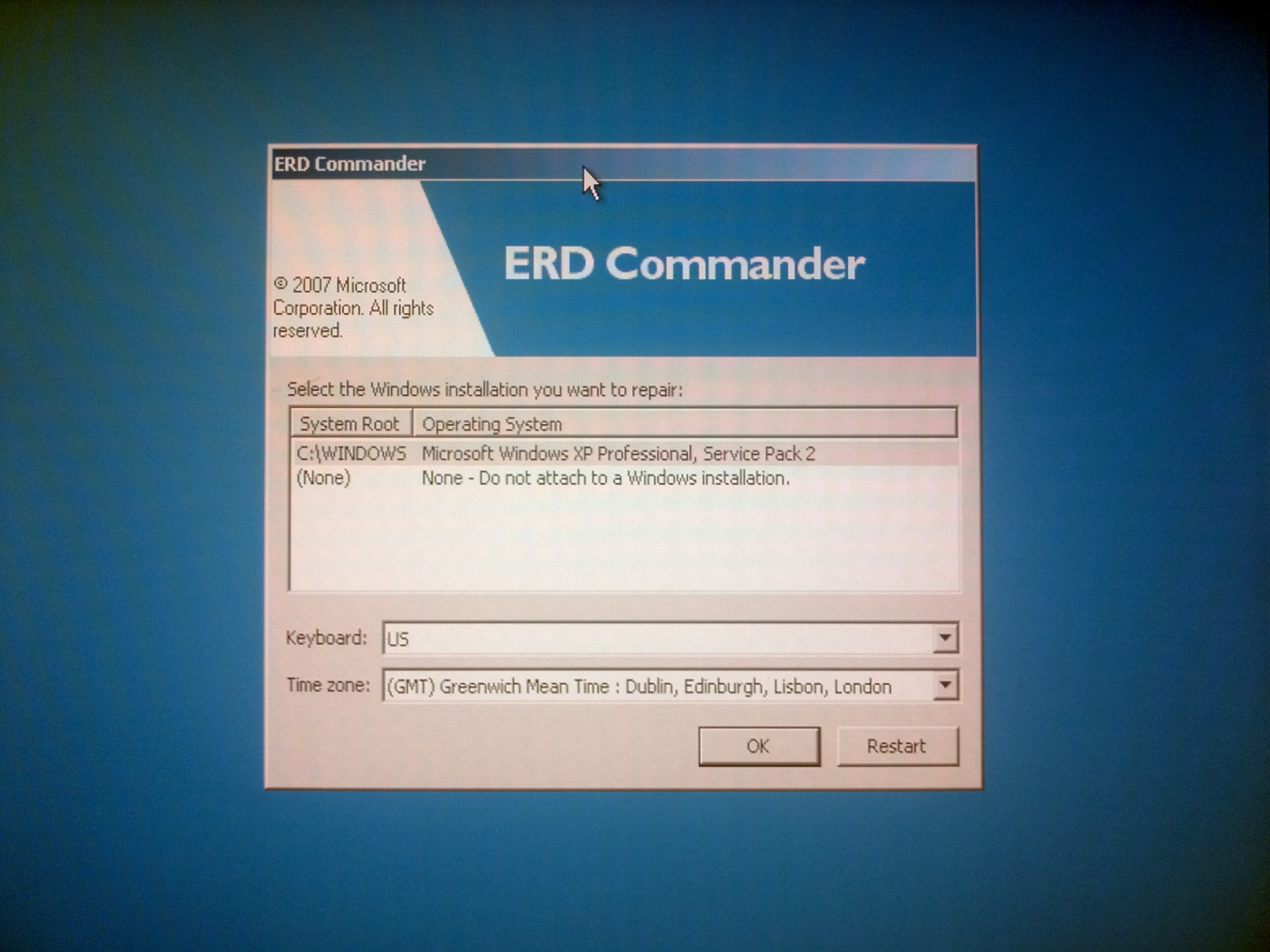
and was able to edit the NAS registry. I have to admit I didn’t know what exactly to look for, but checking for
“HKLM\system\CurrentControlSet\Services\Tcpip\Parameters” is always a good idea, right?
The root cause revealed quickly:
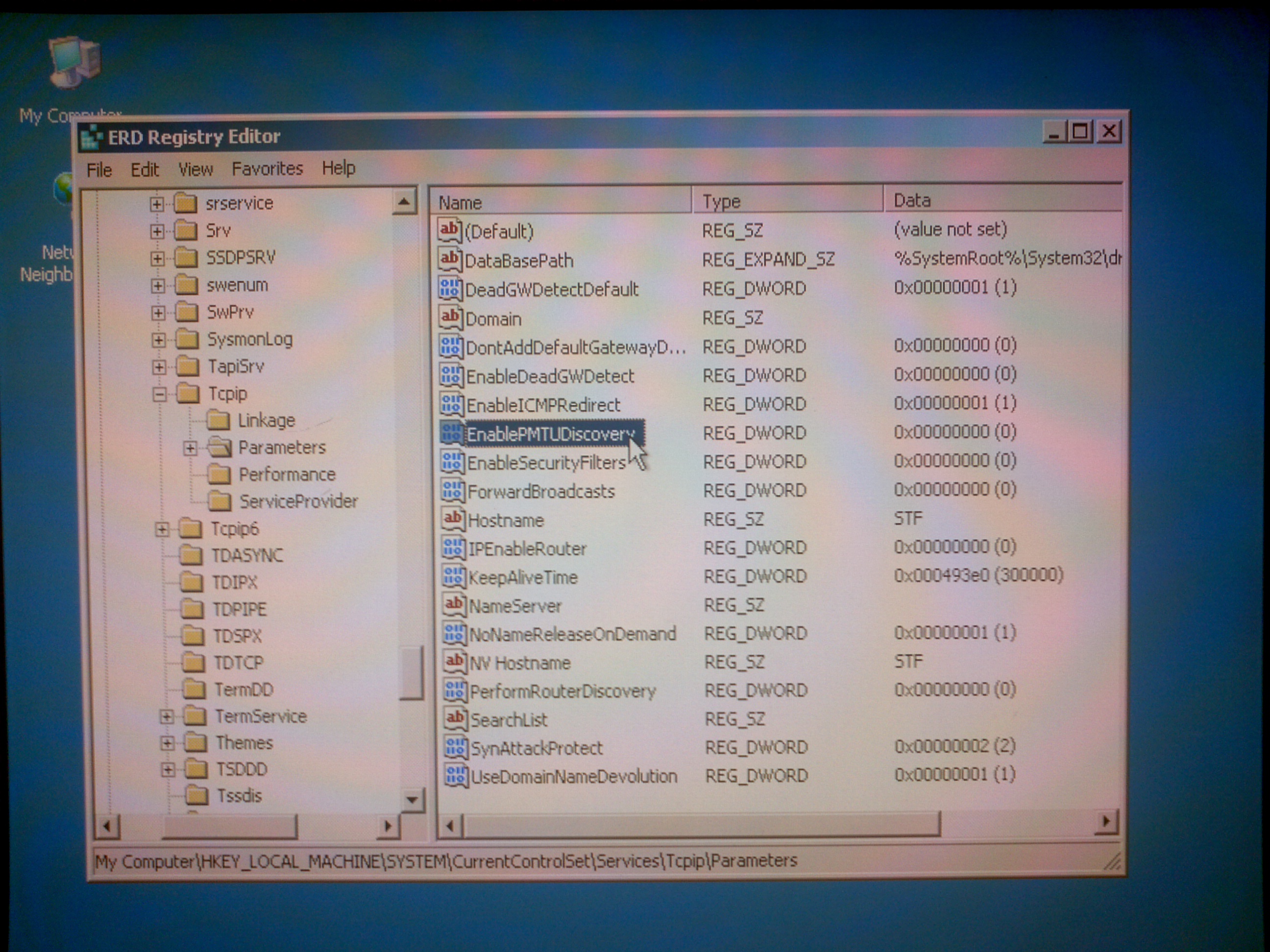
For whatever reason manufacturer just turned PMTUD off. And they left no way to return it back instead of using third party LiveCD. Our NAS device, being not able to determine PMTU, used minimal 576-Bytes PMTU (like it should do) when talking to hosts in another subnet.
So, after a couple of mouse clicks and following reboot that case was finally solved:

Unfortunately, I can’t show you an actual PMTUD process, because I can’t perform server-side capture right now, but anyway frames with 1364-Bytes length clearly indicate that it works now.
Train your brain. Try to answer the following questions:
- Why the first thing I did was the server side capture?
Open PCAP attached (the one with working PMTUD, 192.168.112.77 <–> 192.168.1.169 conversation).
- Look at packets 120-124. Why are they considered “out of order” (not “retransmissions”, not “spurious retransmissions”, not “fast retransmissions”)?
- Why ICMP Type 3 / Code 4 packets from 192.168.1.1 (router IP) have 590-Bytes size?
- Why is packet no. 130 NOT considered “Dup ACK” despite it has ACK number 6469 (relative), the same ACK number as packet no.128 already had? And after that packet no. 132 with the same ACK number 6469 IS again considered Dup ACK.
- What do you think, did the packet no. 133 get to the receiver successfully or got lost on the path?
- Assume you are capturing on a server side. The server has just started to upload quite large file. PMTUD has been already completed, PMTU size has been successfully discovered. What do you think, do you have a chance to see it happening again in the same TCP stream (or caused by the same TCP stream)?
I will post my own answers to these in a week.
Anonymized PCAP (with working PMTUD, LINUX NAS) can be downloaded here: Zipped PCAP
Initial PCAP (no PMTUD, Windows Embedded NAS, anonymized) can be downloaded here: Zipped PCAP
Good read:
- TCP/IP Registry Values for Microsoft Windows Vista and Windows Server 2008
- RFC 1191 Path MTU Discovery.
Hi Vladimir,
great and interesting post!
While reading your post my first thought has been, that if Path MTU Discovery is disabled the Fragmentation Allowed Bit should be activated. But no, Microsoft sets the MTU to 576 as we can see in the linked Registry documentation, too. So well done!
EnablePMTUDiscovery
Setting this value to 0 (not recommended) causes an MTU of 576 bytes to be used for all connections that are not to destinations on a locally attached subnet.
So some people may ask why you didn´t just looked into that kind of documentation. So that´s the part of your article I liked very well. Because the way to reveal the root cause is mostly the hardest part.
And inspired by your article I have to test, if the parameter still works in the same way in actual Versions of Windows.
Hi Christian,
Yes, if I knew that Windows acts this way – I would have solved the issue much faster. But I didn’t and therefore had to use some testing methodology and conversations with tech support guys.
That’s why I wrote that the most experienced readers probably already understand the root cause 🙂
Thanks for the comment!
Hi Jasper, thanks for the feedback!
Yes, you’re right – we must be sure, that there is no manipulation with the headers on the path. And also I have the second part of an answer that I’ll post soon.
Regarding math: that’s true, I’ve fixed it in the article.
Hi Vladimir. I think that the registry setting, “EnablePMTUDiscovery”, was set to a default of 0 in Windows Server versions before 2008. I used to see these payload sizes of just 536 bytes all the time (even though TCP at both ends negotiated 1460). If you ever see them, it is a very strong hint that you’re dealing with Windows 2003 or earlier.
The most interesting behaviour that I ever saw was a Windows client connecting to Bloomberg (via a similar WAN with IPsec setup). The client’s packets were usually under 1460, but whenever they ran a particular function (which sent a full-size 1460 packet) the application would fail. The large packet never made it through the VPN – and hence was never ACKed. ICMP was blocked by the firewall, so the client never received the “fragmentation needed” ICMP packet.
There were two user PCs side-by-side and each behaved differently:
– One would retransmit the 1460 packet twice, then decide to resend all the data in smaller 536 packets (meaning that the application didn’t fail – but did pause for around 15 seconds).
– The other would retransmit the 1460 twice, then send a Reset. Causing an application failure.
I can’t remember what the difference in Windows version was between these two PCs, but it was something like a different Service Pack.
I do remember thinking that the MS developer who implemented the first alternative should have got a pay rise.
Hi Philip,
This is very interesting experience, thanks for sharing it!
I think I’ll do some experiments to see how different Windows versions behave in that case. I’ll share my results after doing that.
And of course to block ICMP is not always a good idea 🙂
Hi Philip,
As far as I can recall, the registry setting “EnablePMTUDiscovery” had always been to a default value of “1” right from Windows 2000 onwards unless there were was an application turning this value to “0”.
However Microsoft has also implement an option to detect black holes calles “EnablePMTUBHdetect”.
A black hole router or Firewall is considered a L3 device that faces a lower MTU on an outbound Interface and with the PMTU discovery message being disabled.. When the router receives an packet with a higher MTU as the outbound MTU and with the “Don’t Fragment” Bit set (due to PMTU discovery), it discards the packet an does not send an ICMP Fragmentation Needed Message.
The sending Windows Station experiencing retransmissions assumes that there must be a Black Hole and lowers the MTU down to 576. That could be the effect you may have seen. Usually the process takes between 2.3 and 20 seconds to recover.
So in the end you have the same result, but a different registry key. And you assumption that it has to do with Microsoft OS version is correct. Microsoft’s default values for “EnablePMTUBHDetect” have been changing over the time back and forth.
Best Regards
Matthias
Thanks for that information Matthias. I dug out the MS document that lists the various Registry settings – and, low and behold, there was the description of “EnablePMTUBHDetect” immediately before “EnablePMTUDiscovery”. I hadn’t noticed it before and so it is great to know exactly why the two Windows PCs behaved differently.
I also found this old 2010 TechNet article that explains why it was common to set “EnablePMTUDiscovery = 0” – as part of server “hardening”. That also explains why I used to see it very often in the company I worked for.
https://blogs.technet.microsoft.com/nettracer/2010/06/01/do-you-still-set-enablepmtudiscovery-to-0/
I’m really pleased to have learned just that little bit more about these things and to have explanations for the past observed behaviours. Thanks to you (and Vladimir for taking the trouble to write the blog).
Regards, Phil.
Hi Vlad,
Excellent TS technic!!! I really liked the way you outlasted support. We all have these non-support support stories.
Along the goal of maintaining large MSS yet preventing fragments, I have been thinking we should always set MTU to less than 1500. Cisco VPN chose 1300 so we get 1260 MSS vice 1460–not to less efficient. I would maybe use MTU=1400 so we could tell it was us. Your thoughts?
Hi Mark,
thanks for the feedback!
Regarding MTU this is cool question. Let me think about it and also maybe gather some additional information. I’ll keep you informed!
Hi,
well set the MTU less then 1500 is in option.
But I would use this option only, if I have reliable problems with PMTUD.
However this could be happen when I can´t use PMTUD for example if I use UDP or Multicast traffic.
But again this needs a very smart implementation from my point of view.