У меня есть практика время от времени проводить baselinig в нашей офисной сети. В один момент я решил по плану помониторить трафик на VPN-канале между офисами. И обнаружилась такая интересная картина в трафике с сетевого накопителя (NAS).
Проблема
Явно проглядывается особенность, которой там быть не должно. Попробуйте потренировать мышление и угадать с одного взгляда:
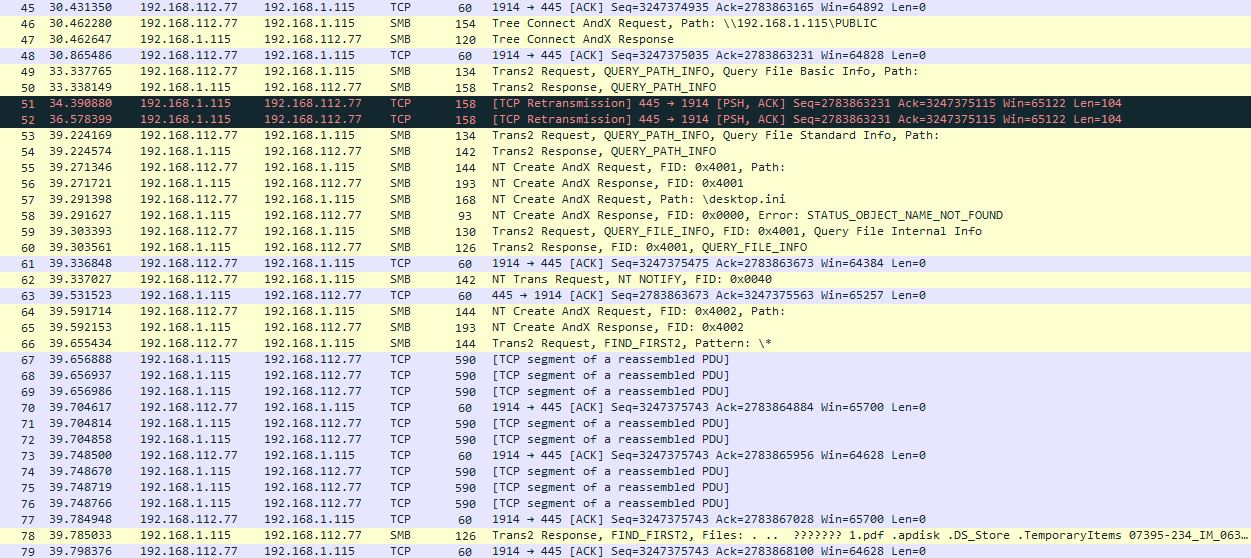
Получилось? Что думаете? Ваши предположения?
2 переотправки пакетов (51,52)?
Возможно. Тем более в том месте большой зазор по времени между пакетами 50 и 53 – целых 6 секунд. Это многовато, и стоило бы разобраться, откуда он взялся. Но – я должен признаться, что на скриншоте немного зачищенный дамп, и там под раздачу попал NFS-трафик, который я отфильтровал как не имеющий отношения к вопросу. То есть, 6-секундная задержка была заполнена соединением по NFS.
А сейчас я предлагаю присмотреться к пакетам (правильнее, конечно, “кадрам”, но для простоты я буду называть их “пакетами”), начиная от номера 67. Они все 590-байтные. Почему нам это должно быть интересно? Ведь до этого момента времени полно ещё меньших по размеру пакетов. А интересно это потому, что до пакета 67 у нас был командный трафик, и потому небольшой размер – это нормально. А после начинается передача данных, нагрузки (обратите внимание на подпись “TCP segment of a reassembled PDU”). То есть, это fully-loaded пакеты такого размера. Почему же они такие маленькие, ведь по теории можно их паковать по 1514 Байт (ну, или если у нас по пути туннель, то немногим меньше)?
Подозреваю, что некоторые (или даже многие) опытные из вас уже догадались о причине и вообще обо всем происходящем в данном случае. Но давайте просто пошагово продвигаться в анализе, чтобы выработать какой-то осмысленный подход к процессу. Ну и заодно посмотрим мою переписку с техподдержкой производителя.
Итак, с чего начнем?
Хорошая практика – проверить 3-way handshake, может, там сразу будет зацепка:
![]()
Пока все выглядит нормально – оба устройства готовы принимать MSS 1460 Байт, window scaling включен. Правда, накопитель анонсировал window scaling = 1. Маловато. Это проблема? Потенциально – да, может сказаться на скорости на линках с большим RTT, но в данном случае накопитель передает данные, и его окно приема не настолько критично.
Следующий шаг. Теперь нам нужно обязательно знать, где мы находимся. Проверим тайминг в 3-way handshake, чтобы это вычислить. Это очень важно для того, что называется situational awareness – зная, свое местоположение в сети (точку захвата), мы можем восстановить происходящее более корректно. Итак, мы захватываем трафик на стороне сервера. Откуда узнали? Всё просто, зазор между пакетами 1-2 на порядок меньше, чем между 2-3. Признаюсь, первый раз, когда я захватывал трафик с этого накопителя, это происходило на стороне клиента, но потом я перезахватил дамп на серверной стороне (угадайте, с какой целью? Чего я хотел этим добиться?)
Дальше. Теперь было бы неплохо вообще разобраться в структуре сети. Всегда, производя подобный анализ, нужно иметь в виду структуру сети. Для чего? Чтобы знать, кто и как себя может вести, какое влияние оказывать. Итак, клиент находится в подсети 192.168.112.0/24, NAS находится в подсети 192.168.1.0/24. Географически NAS вообще находится в другом офисе, в другом городе. В том же сегменте есть ещё один NAS, и это хорошо – можно будет при необходимости посмотреть, как ведет себя он. Запомним это для себя на всякий случай.
Между офисами проброшен простой site-to-site IPSec VPN:
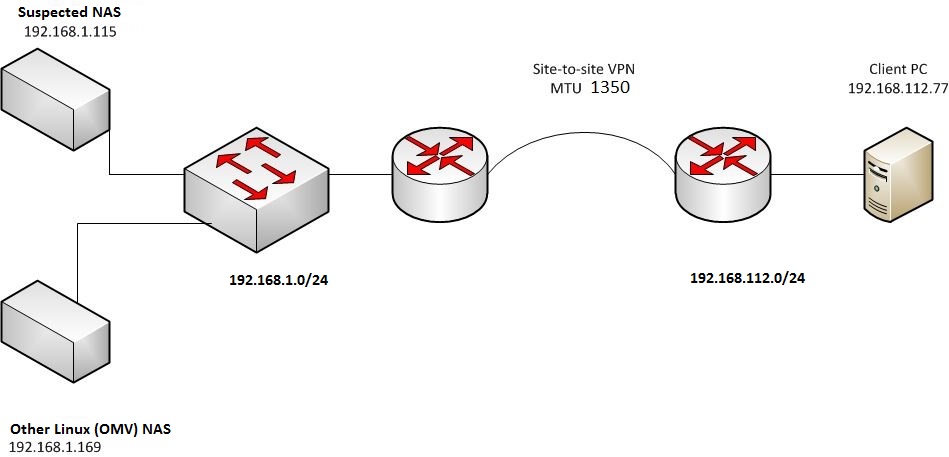
Хорошо, что делать дальше? Давайте, попробуем захватить трафик с того же NAS’а (192.168.1.115), но внутри локального сегмента (в пределах 192.168.1.0/24, исключим маршрутизаторы по пути). Результат – все так, как и должно быть по правилам, пакеты по 1514 Байт. То есть, одно и то же устройство шлет 590-байтные пакеты, если видит, что клиент в другой сети, и 1514-байтные, если видит клиента в той же (своей) подсети.
Заподозрив, что в данном случае проблема в настройке накопителя, я сделал запрос в техподдержку производителя с описанием всей ситуации и прикрепленными дампами.
И вот что получил в ответ:
“…В отношении Вашей проблемы. Как я понимаю, когда вы используете накопитель в пределах одной подсети, размер пакетов 1500 Байт. Но когда Вы пытаетесь работать с накопителем из другой подсети, размер уменьшается до 576 Байт.
Исследовав этот вопрос в Интернете, я подозреваю, что проблема где-то в Вашей сети, которая ограничивает размер пакетов…”
..И внизу была прикреплена ссылка на страничку с описанием PMTUD.
Ладно, я понял. Ответ типа “это всё ваша сеть”. Но в туннеле максимальный размер пакетов ограничен 1350 Байтами, а не 576-ю. Вот теперь нам придется собрать более весомые аргументы.
Специально для техподдержки я захватил ещё один дамп, но теперь с другого NAS’а (недаром мы про него запомнили), стоящего рядом с первым подозреваемым. У него на борту установлена OpenMediaVault OS, и его айпи 192.168.1.169. Итак, смотрим, оцениваем:
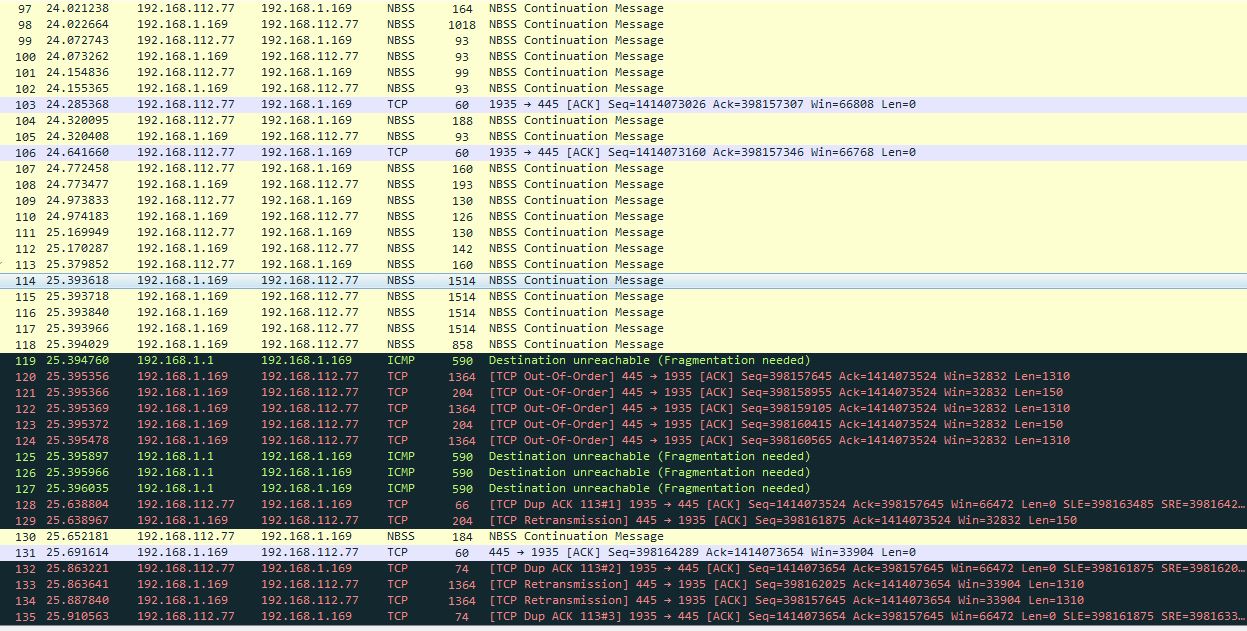
Видите разницу? Вот теперь это настоящий PMTUD. Во-первых, давайте посмотрим на пакет 98. Его размер 1018-14=1004 Байта (это на L3). И он без проблем пролез в туннель! (В общем-то, я и так был вполне уверен, что это произойдет, но дополнительная проверка никогда не помешает).
Потом в туннель полетели 4 полных пакета по 1514 Байта (114-117). И вот эти товарищи уже дропнулись на роутере, а в ответ от роутера нам прилетели ICMP Type 3 / Code 4 / Destination unreachable (Fragmentation needed).
Присмотримся подробнее к этим ICMP-ответам:

Маршрутизатор явно говорит нам, что в туннель пролезает только 1350 Байт за раз (поле “MTU of next hop”). Всё работает как надо!
После того, как OMV-NAS получил “ICMP-ответку”, он раздробил исходящие пакеты на 2 части каждый (1364 и 204-байтные Ethernet-кадры соответственно) и отправил их попарно заново.
Займемся несложной математикой (например, пакеты 120, 121):
1364 – 14 (L2 заголовок) = 1350 Байт. 1350 – 40 (L3 заголовок + L4 заголовок ) = 1310 Байт в первом ТСР-сегменте (что и написано справа в поле Len=1310).
204 – 14 (L2 заголовок) = 190 Байт – 40 (L3 заголовок + L4 заголовок) = 150 Байт во втором ТСР-сегменте (аналогично).
Итого: 1310 Байт + 150 Байт = 1460 Байт – а это и есть MSS, который анонсировался в 3-way handshake. Всё совпало до последней цифры!
Вывод – так как второй накопитель отработал как положено, проблема с сетью маловероятна.
Уже после этой проверки я снова написал в поддержку:
“Спасибо за ссылку, я почитал, но где вы, собственно, видите, чтобы срабатывал PMTUD? Процесс должен был выглядеть следующим образом (тут я прикрепил второй дамп, с Linux-OMV-NAS)
В ожидании ответа (к слову, в этот раз с ответом явно стало затягиваться) я почитал RFC1191. Возможно, удастся наскочить на что-то касательно данного случая.
“Actually, many TCP implementations always send an MSS option, but set the value to 536 if the destination is non-local. This behavior was correct when the Internet was full of hosts that did not follow the rule that datagrams larger than 576 octets should not be sent to non-local destinations. Now that most hosts do follow this rule, it is unnecessary to limit the value in the TCP MSS option to 536 for non-local peers.”
Похожая ситуация. NAS выставляет 1460 Байт TCP MSS в 3-way handshake, и он же следует правилу отправлять 576-байтные пакеты “нелокальным” (не в своей сети) получателям…
А тут и подоспел очередной ответ:
“Можно попробовать вручную выставить параметр MTU на NAS. Попробуйте выполнить команду:
netsh interface ipv4 set subinterface “Local Area Connection” mtu=1300 store=persistent
в командной строке.”
Анализируем ответ. Звучит очень спорно.Команда изменяет MTU в общем, независимо от подсети, а ведь в локальной подсети все работает нормально! Значит, MTU там больше. Но так или иначе, я не смог этот совет выполнить, потому что на борту у накопителя была Windows XP Embedded (да-да, это настоящий динозавр). И вот эта ОС мне не позволила получить доступ к командной строке. Она по сути своей очень обрезана, вместо Explorer’а там какая-то кастомная оболочка с парой окон.
Поэтому после ещё пары писем (ничего интересного) в поддержке сломались и ответили, что тут бы надо вносить изменения в прошивку, а делать они уже этого не станут, т.к. устройство – да, динозавр, и никому не интересно, в общем, простите, до свидания.
Решение
На этом этапе можно было уже и сдаться – ведь нам удалось доказать, что виновата прошивка накопителя, техподдержка успешно слилась.. К тому же накопитель-то по сути работает, пусть и неоптимально. И тут внезапно, заехав в тот второй офис (я бываю там не так часто), я попробовал и успешно зашел в БИОС накопителя! И там оказалось возможным даже выбрать порядок загрузки, и можно выставить “USB first”.
Я скачал и записал диск ERD Commander, подкинул USB привод и загрузился с него…
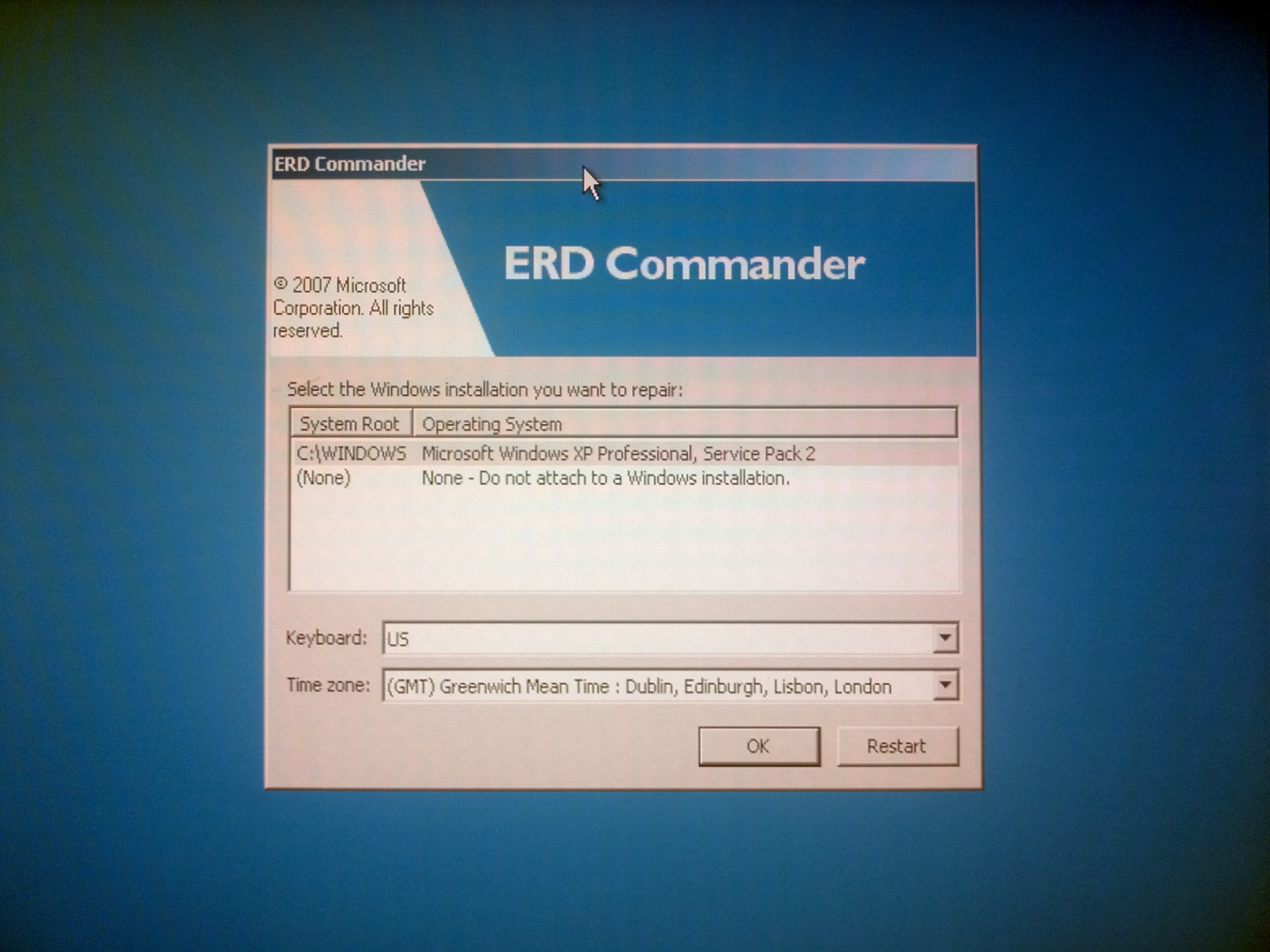
Прекрасно, я могу подключиться к установленной Windows XP Embedded и заглянуть в реестр. Пока точно не знаю куда, но ведь есть содержательная ветка
“HKLM\system\CurrentControlSet\Services\Tcpip\Parameters” ,
там можно посмотреть, что задано на тему сетевого стека.
А вот и причина всего безобразия:
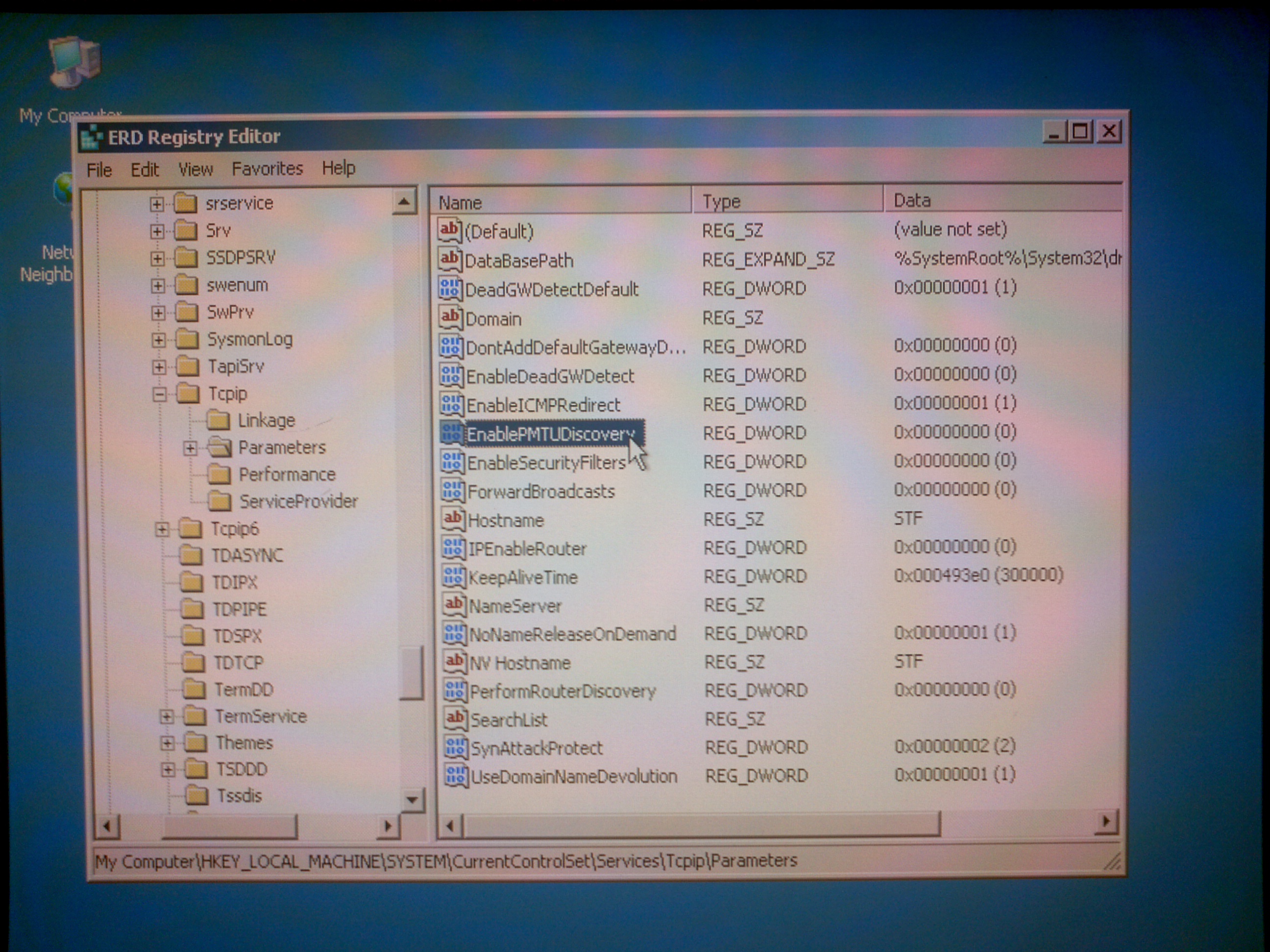
Непонятно зачем, но сам же производитель выключил PMTUD в своей прошивке. И не оставил никакого способа вернуть все на место, кроме как использовать сторонний LiveCD. Естественно, NAS, будучи не в состоянии определить размер PMTU (этот механизм ему выключили), на всякий случай уменьшал PMTU до размера 576 Байт. А что такое 576 Байт? Это величина PMTU, которая согласно RFC должна обязательно форвардиться маршрутизаторами без разбивки на фрагменты.
В итоге, вся история решилась парой кликов:

К сожалению, теперь я не могу показать, как происходит процесс PMTUD – не имею доступа к тому накопителю. Однако, одного дампа с клиентской стороны достаточно, чтобы увидеть, что проблема решена.
Потренируемся? Попробуйте ответить на следующие вопросы:
- Почему первое, что я сделал – это захватил второй дамп на стороне сервера (накопителя)?
Откройте прикрепленный PCAP (это дамп с рабочим PMTUD, 192.168.112.77 <–> 192.168.1.169 соединение).
- Посмотрите на пакеты 120-124. Почему они отмечены как “out of order” (не “retransmissions”, не “spurious retransmissions”, не “fast retransmissions”)?
- Почему пакеты ICMP Type 3 / Code 4 от 192.168.1.1 (это IP роутера) все размером по 590 Байт?
- Почему пакет 130 НЕ считается “Dup ACK” несмотря на то, что его ACK number = 6469 (относительный), такой же, какой УЖЕ был в пакете 128? А потом снова пакет 132 с тем же ACK number 6469 СНОВА считается Dup ACK.
- Как вы думаете, пакет 133 добрался до получателя или потерялся где-то по пути?
- Давайте предположим, что мы захватываем трафик на стороне сервера. Сервер только что начал передачу большого файла. PMTUD уже произошел успешно, размер PMTU определился. Как вы думаете, есть ли у нас шанс увидеть этот процесс (PMTUD) снова в том же ТСР-соединении?
Дамп после анонимизации (с рабочим PMTUD, LINUX NAS) можно скачать здесь: Zipped PCAP
Первый дамп (без PMTUD, Windows Embedded NAS, анонимизированный) можно скачать здесь: Zipped PCAP
Что почитать:
- TCP/IP Registry Values for Microsoft Windows Vista and Windows Server 2008
- RFC 1191 Path MTU Discovery.
Автор: Владимир Герасимов
Перепечатка без согласования запрещена!
1
Хорошая статья.
А изложить правильные ответы на свои вопросы?
Добрый день, Андрей!
Хорошо, сделаю. Давно собирался, но закопался в работе.